An eval score going down is more useful if you know why. In practice, knowing that a model’s score dropped from 72% to 68% between versions tells you something is worse — but it tells you nothing about what broke or where to look. That gap between “the eval says something is wrong” and “now I know what to fix” is the motivation behind ProbeLLM: Automating Principled Diagnosis of LLM Failures.
The problem with static benchmarks
Most LLM evaluations work the same way: assemble a fixed set of questions, run the model, report a score. The problem is that this does not guanrantee you know why something fails. As the paper puts it: “most evaluations remain static snapshots of model behavior… as models evolve, their error distributions shift accordingly, which makes it difficult for static evaluations to surface emerging weaknesses.”
The obvious fix is to go looking for new failures — not just count the ones you already know about. ProbeLLM automates that search.
An oral exam for AI
The core idea clicked for me when I thought of it as an oral exam. A written test gives every student the same fixed questions. An oral exam works differently: when a student’s answer signals shaky understanding of a topic, the examiner probes deeper — generating new questions on the fly, right where the weakness shows up.
ProbeLLM does the same thing with AI evaluations. It starts with an existing benchmark — a fixed set of questions with verifiable answers — and uses that as a jumping-off point. An LLM with tools generates new questions, verifies their ground-truth answers automatically, and adds them to the search. The result is a dynamic probe that grows toward where the model is failing.
The search is organized as a tree, where each node is an eval question. The algorithm explores this tree using Monte Carlo Tree Search. It favors nodes that have been visited rarely but have a high failure rate among their children — this is the same strategy used by professors during oral exams. Any topic where the student is shaky, but have not been adquately explored, is up next.
Breadth and depth
At each step, the algorithm chooses between two modes of exploration.
Macro refinement is for breadth. It looks at clusters of existing questions in embedding space and proposes something in a new region — a different type of question, a different topic. The goal is to find new sfailure modes.
Micro refinement is for depth. It takes a question where the model failed and makes a small variation — changing a detail while keeping the core topic unchanged. The goal is to understand exactly what about the question trips the model up: whether it is the phrasing, the complexity, or a specific concept.
The two modes balance a constant tension in evaluation: breadth versus depth. We want to cover new ground, but also to understand the failures we’ve already found. Making this tradeoff explicit and algorithmic is one of the things I find most compelling about this approach.
From failures to failure modes
Once the search is done, ProbeLLM clusters the failure cases. Each failure is represented by the question and the an LLM-generated error description, mapped into an embedding space. Clustering groups together failures in the embedding space, and then representative descriptions are mapped back into natural language — producing a human-readable summary of each failure mode.
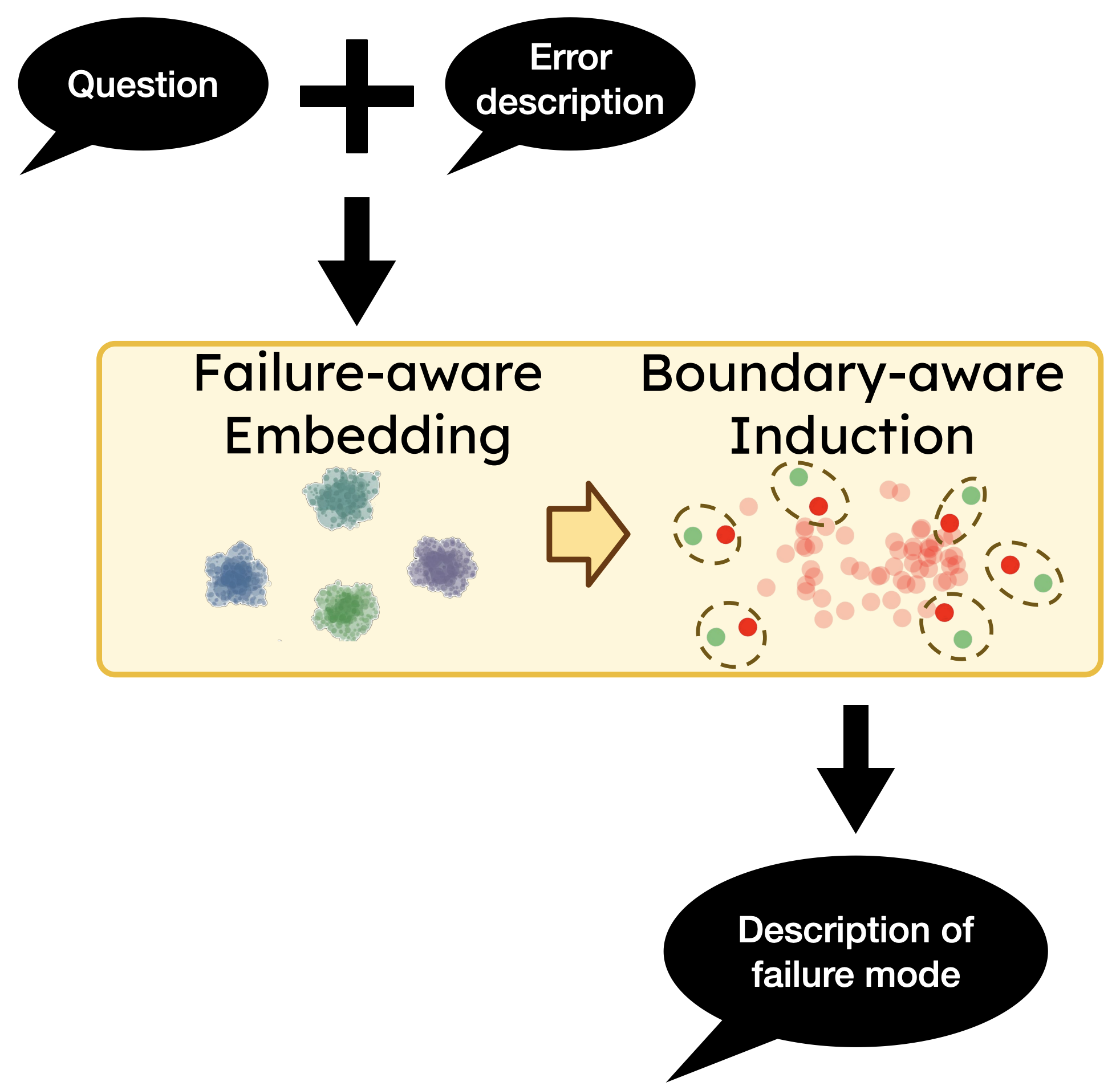
Each failure case is represented by the question and an LLM-generated error description. This text gets mapped into a high-dimensional embedding space, where clustering groups similar failures together. Then, samples are drawn near the boundaries of each cluster. Each sample is mapped back into natural language description, which gives an example of the failure mode.
Across four models (Deepseek-v3.2, Llama-3.1-8b-instruct, Claude-3.5-sonnet, and Ministral-14b), ProbeLLM consistently found more failure modes than static benchmarks alone. For Llama-3.1-8b-instruct, static benchmarks found 8 distinct failure clusters; ProbeLLM found 24, with 16 that the benchmark never surfaced. For Claude-3.5-sonnet: 5 from the benchmark, 15 total, with 10 that ProbeLLM found on its own.
What I’m still thinking about
ProbeLLM requires questions with verifiable answers, because the refinement step needs to check ground truth automatically. Agentic evaluations — where the model uses tools and the “right answer” depends on the full trajectory of a multi-step task — don’t satisfy that requirement. The paper also only evaluates base LLMs, not agents. For agents, a failure in the final answer might have its root cause several tool calls earlier. Whether this kind of diagnosis can extend to agentic settings is an open problem.
I’m also still thinking about the failure mode clustering step. Mapping failure cases into embedding space and applying well-established clustering algorithms is statistically sound and operationally scalable. But, turning the identified clusters in high-dimensional space back into human-understandable content involves smart sampling strategies. Maybe this could be simplified. LLMs already operate by turning input text into embedding space vectors and then decoding the response to get back natural language, so we could simply give all the failures to a language model and ask it to summarize why the scores changed. Sure, it could hallucinate, but this is a fast way that does not involve extra infrastructure.
My takeaways: 1. failure diagnosis is super necessary to make evals actionable. 2. But, this is a hard thing to do because you need to balance breadth and depth of the search. This paper gives us a concrete recipe that we can implement in our own ways.
Paper: ProbeLLM: Automating Principled Diagnosis of LLM Failures, Huang et al., 2026.